Title
Authors
Details
- Published on
- 2024-11-01
- Published in
- The 2024 Conference on Empirical Methods in Natural Language Processing
- Link
- [ paper ]
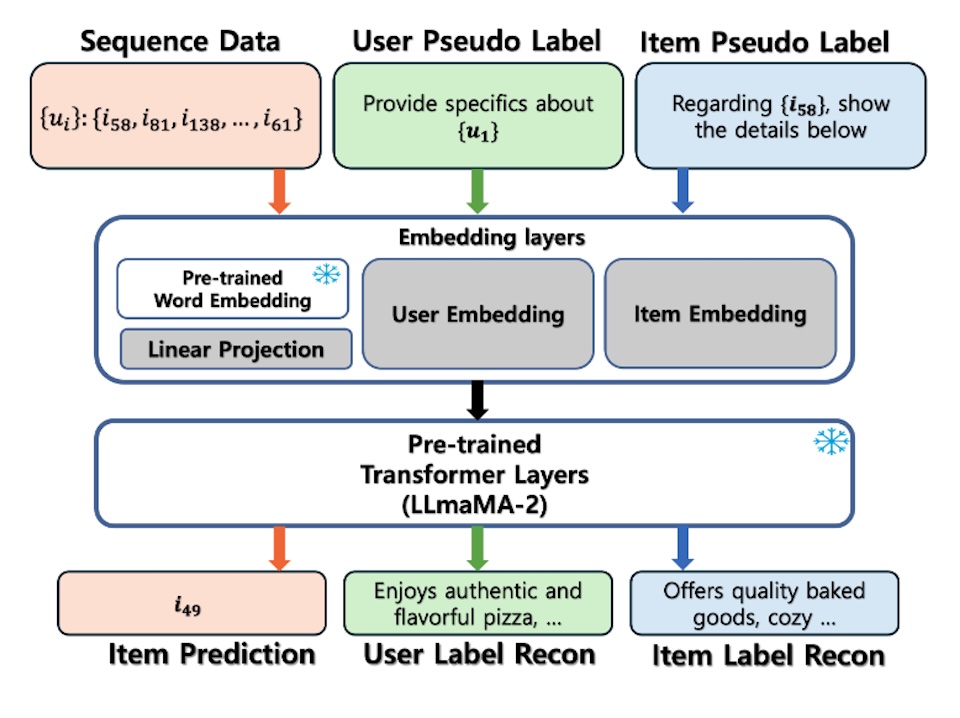
Abstract
Large language models (LLMs) are utilized in various studies, and they also demonstrate a potential to function independently as a recommendation model. Nevertheless, training sequences and text labels modifies LLMs’ pre-trained weights, diminishing their inherent strength in constructing and comprehending natural language sentences. In this study, we propose a reconstruction-based LLM recommendation model (ReLRec) that harnesses the feature extraction capability of LLMs, while preserving LLMs’ sentence generation abilities. We reconstruct the user and item pseudo-labels generated from user reviews, while training on sequential data, aiming to exploit the key features of both users and items. Experimental results demonstrate the efficacy of label reconstruction in sequential recommendation tasks.