Title
Authors
Details
- Published on
- 2026-03-24
- Published in
- The 19th Conference of the European Chapter of the Association for Computational Linguistics
Abstract
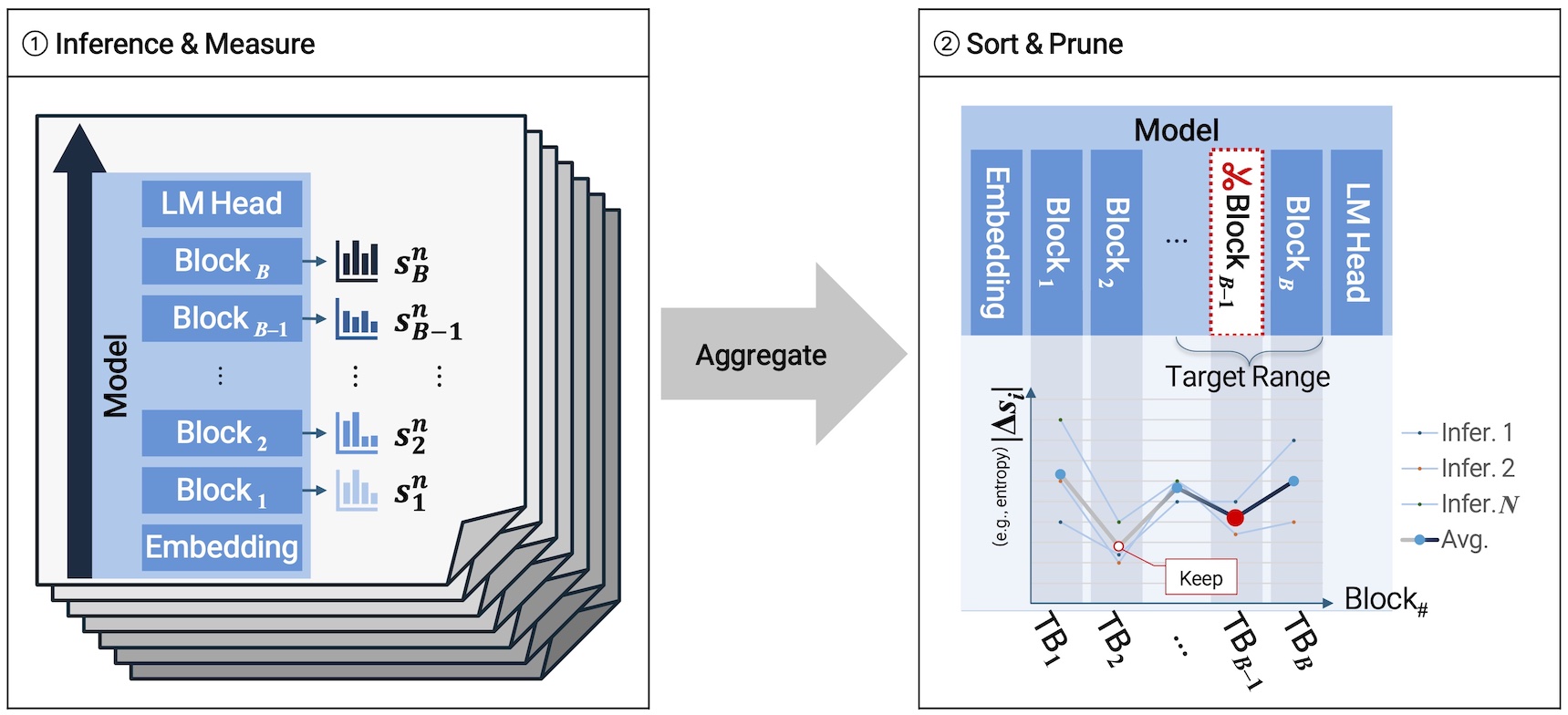
Large language models (LLMs) provide excellent performance, but their practical deployment is limited by significant inference costs. In particular, the large model size results in high computational overhead, increased memory usage, and slow inference latency during auto-regressive decoding. To mitigate these inference-time inefficiencies while preserving model structure, block pruning has emerged as a practical solution by reducing the number of executed transformer blocks during inference. By operating at a structural level, block pruning can effectively reduce latency without disrupting architectural coherence. However, existing methods typically rely on representation similarity or computationally expensive sensitivity analyses to estimate block importance, thereby neglecting task-aware model behavior. To address this limitation, we introduce Task-aware Block Pruning (TaBP), a novel pruning approach that directly captures task-specific inference dynamics by quantifying block-level uncertainty from statistics of each block’s early-exited output distribution on a calibration dataset. Since output distributions reflect the model’s confidence and decision uncertainty conditioned on downstream tasks, these statistics provide a principled signal for identifying blocks that are less critical for task performance. Here, we introduce a novel block-pruning method that quantifies block-level uncertainty by measuring statistics on each block's early-exited output distribution on a calibration dataset, in order to identify prunable blocks. Extensive experiments demonstrate that TaBP preserves downstream task performance while substantially reducing inference latency and computational cost, without relying on cost-heavy sensitivity analyses.